

These photorealistic photos of Trump getting arrested go viral on Twitter. We're getting close to the day where we no longer will be able to tell what's real and what's AI-generated. With Midjourney V5, we may already even be there. pic.twitter.com/0Plt9F5dxH


Want to grow your newsletter with ads? Use these 5 tools for inspiration: - TikTok creative center - Find top ads, trends, & sounds - FB ad library - Spy on your competitors - Swipefile .com - Library of all ad types - Moat .com - Banner ad library - Swiped .co - Classic ads

10 Visuals That Will Make You Think => 1: The difference between trying to hold onto your thoughts and writing them down. pic.twitter.com/DhGW9Z6sAq


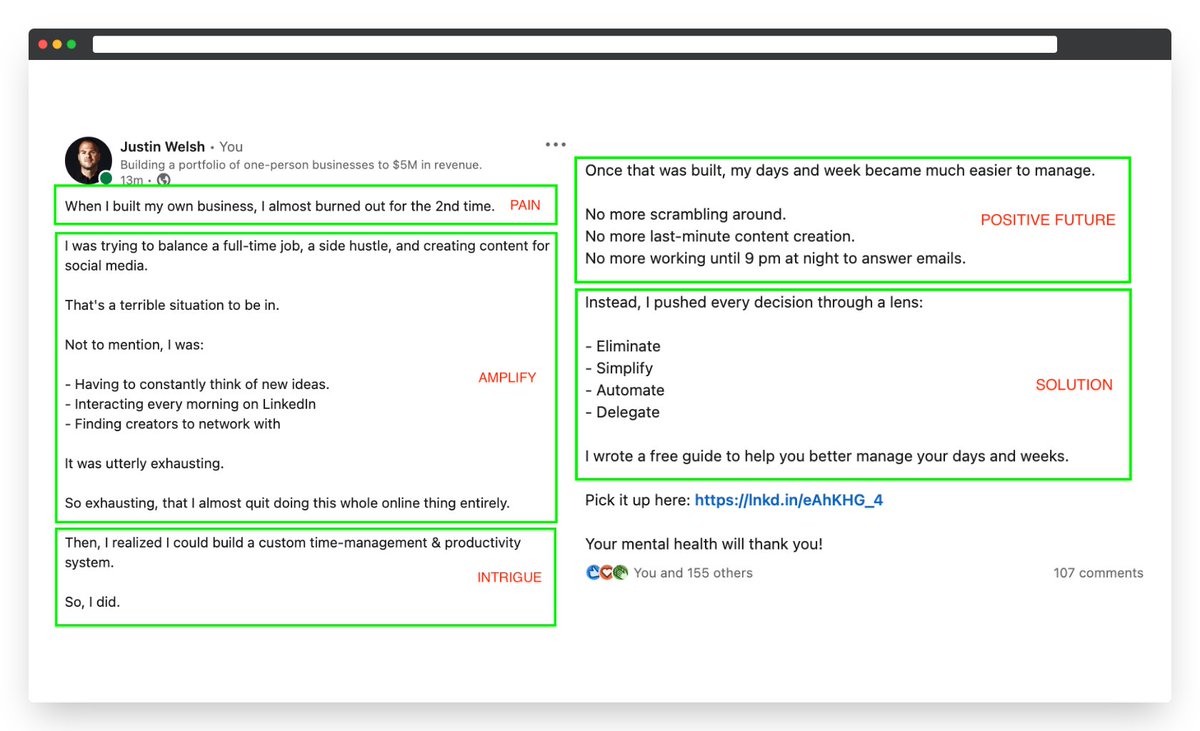
LinkedIn loves stories. Pain → Amplify → Intrigue → Positive future → Solution pic.twitter.com/5s1m3ZoDqv

@commandodev First public save of this thread! 🏆 Readwise users: Like this reply to save gregisenberg's thread to your account without cluttering their replies 📚 Stats: • 2508 total saves of gregisenberg's threads (ranked #14)

I study 200 YouTube channels every week. All I do is read video titles, look at how many views they got, and try to find patterns between successful videos. Here are 10 phrases I see working each week:

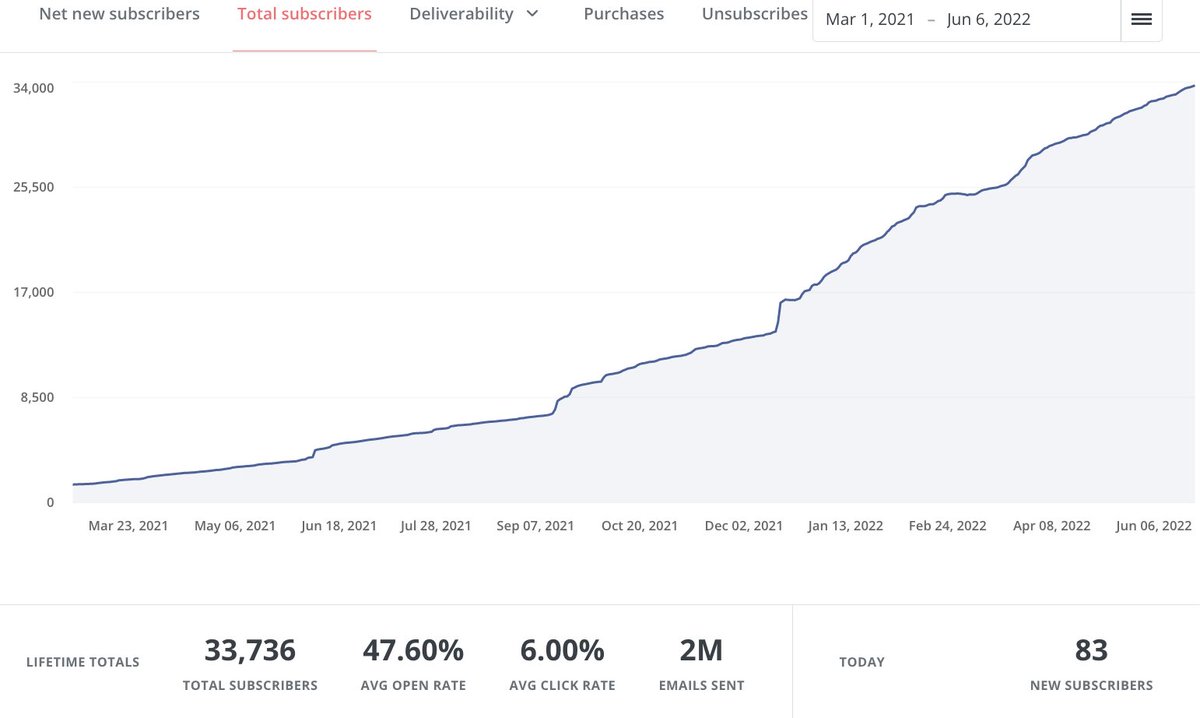
It took 12 long months to get our first 3000 newsletter subscribers We’ve added 4000+ subscribers in the last 9 weeks Here’s what changed:


Are you guilty of being a wannabe? I want to start a business. I want to lose weight. I want to make content. I want to be present. I want to serve others. I wanna… New rule: say I am. Take action. Do or do not. The more you say & the less you do, the less credibility you have.

This dead-simple system will help you say 1 idea in 1,000 unique ways (so you never stare at a blank page again). It's called the 4A Framework – here's how it works:

Current goal: grow our newsletter from 35k to 100k in 6 months. Here's the game plan: • Write 1 absurdly valuable email per week • Repurpose emails as Twitter threads & LI posts • Link to email list as reply to individual tweets & LinkedIn posts Feel free to copy! pic.twitter.com/LFQm3OrCri

Treat Twitter as a job for 6 months and you’ll be never out of work again.

YouTube is a free Web3 university. But 98.8% don't subscribe to the right channels. So, I've audited 120+ YouTube Channels, and here are 23 of the very best to 10x your Web3 journey:

I make a living building stuff with no-code. But I've never bought a “no-code course.” Because truth is, 95% of the information you need can be found on the web for free. So here're my 5 go-to resources to become a money-making no-code builder for $0:


Twitter can be a powerful success accelerator or the #1 thing that holds you back. It's all about how you use it.

25,137 subscribers just learned 4 Twitter copywriting mistakes. Today's issue covers how to: 1. Craft better opening lines 2. Eliminate Sophisticated jargon 3. Reformat Tweets for better reading 4. Alleviate audience blame vs. finger-pointing. justinwelsh.me/blog/5212022

Over the past 15 months, I've spent 1,000+ hours operating a 7-figure online course. During this time, I've tried 50+ tools. And truth is, you only need 6 to launch your first course. So stop wasting time choosing & start with these:
This is so interesting: Watch @MarkNorm develop a standup bit from vague conception to trying it in front of an audience: youtube.com/watch?v=OnWGWp…
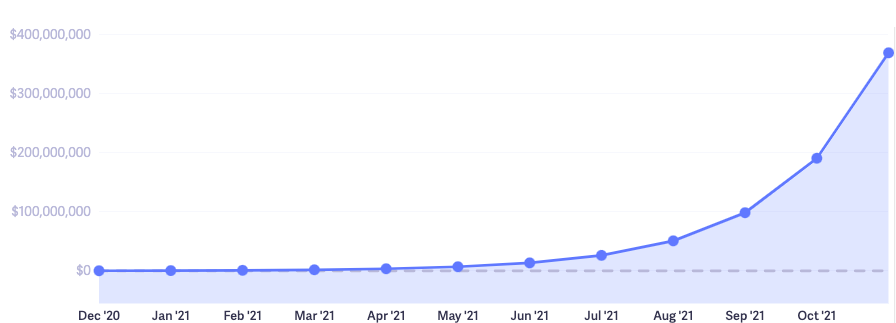
I made $2m flipping a SaaS startup in 18 months following these 4 steps. Read how I did it to make your first million. pic.twitter.com/tkmEkmbXZn
I’ve done $2M in income in 2.5 years as a solopreneur. And I didn't write a single line of code. My 14 "must use" no-code tools: [🧵 thread]
Time to dust off the corporate law textbooks... "Would Elon win if he sued Twitter’s Board?" Doubtful. In this case, it’s actually pretty cut and dry. But this could get a lot more complicated if Elon wanted to make it so. Here's why:
Tell people you hate your job & nobody bats an eye. Tell people you're going out on your own & get lectured on risk.
Imposter syndrome keeps most people from doing what they truly want to do. That’s why I’m not a hater in people who “talk themselves up.” Sometimes the best way to get there is to pretend you’ve already made it. Keep at it fam!
Solopreneurship 101: - Learn a skill at work - Consult with that skill for a reasonable rate - Learn about your customer's most pressing needs - Niche down to solving only that and raise your rates - Productize everything else you learned and sell it online
Want a sneak-peek into Ship 30 for 30? Here's a visual breakdown of our core frameworks:
Interested in, just signed up to or finished #ship30for30? Here’s a visual recap of 5 key ideas from Ship30 in one 🧵, to: ✍️ go from novice writer to pro 💬 build your audience 💰 make money online All in 10 mins. @dickiebush @Nicolascole77 pic.twitter.com/5BtOvCCsGJ
