

Concept of SQL joins. pic.x.com/sx3hfsktaz



SQL is not that hard. You haven’t just seen this. pic.x.com/9ry46s5ybg

Fun read: Just use Postgres news.ycombinator.com/item?id=339341… 👉 caching (instead of Redis) 👉 message queue 👉 data warehouse 👉 olap 👉 json store 👉 cron 👉 geo 👉 full-text search 👉 apis 👉 auditing 👉 graphql What else can you do with Postgres? @supabase any ideas?

pg_savior: A Postgres extension to save you from accidental deletes github.com/viggy28/pg_sav… @PostgreSQL's hook system is so powerful, but looks like very little material about it.

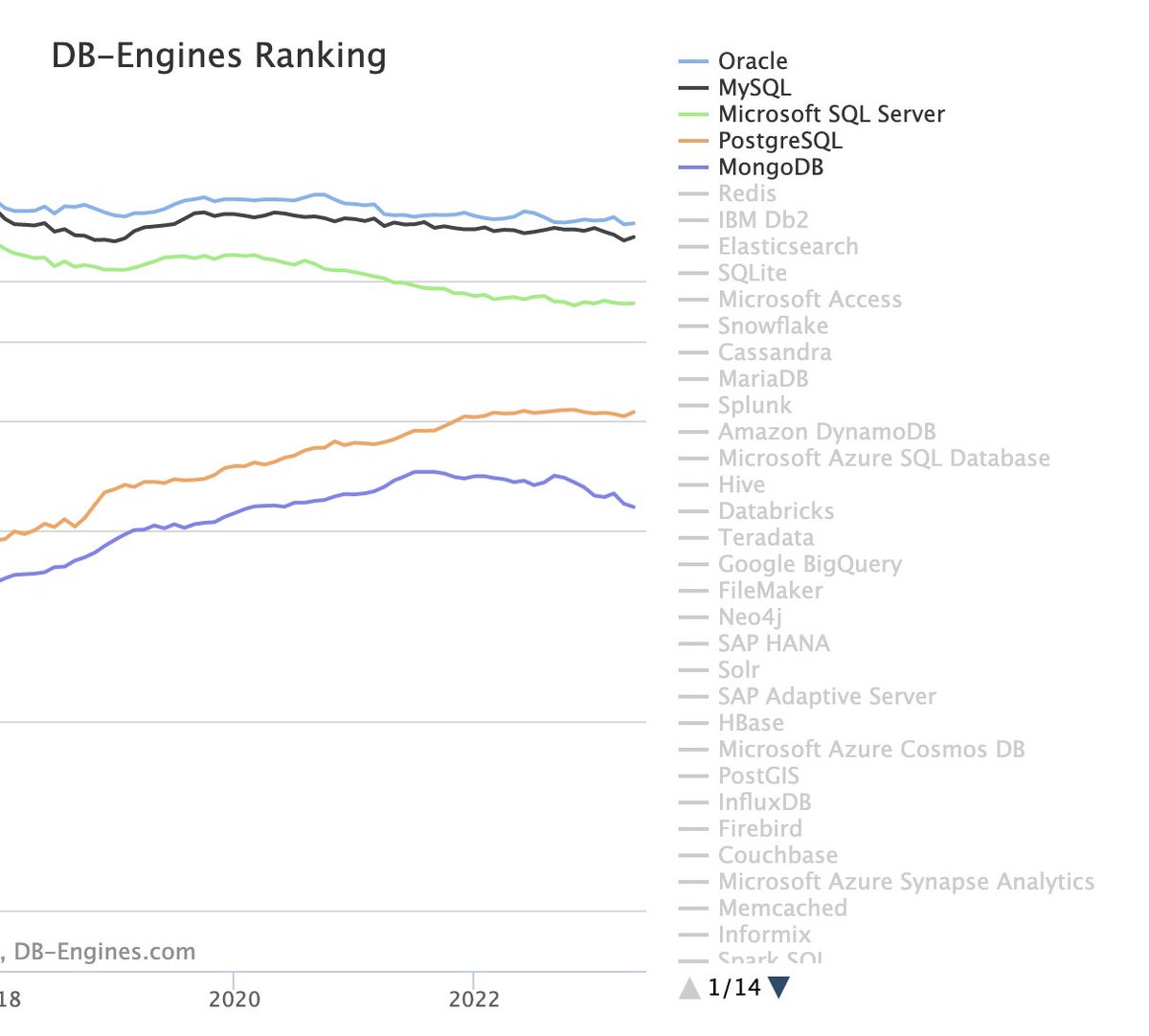
Postgres keeps driving share. The only top 5 database with an upwards trend: db-engines.com/en/ranking_tre…. Mongo and SQL Server are in trouble. Oracle and MySQL - melting ice cubes. twitter.com/i/web/status/1… pic.twitter.com/UvpyCWNMZH

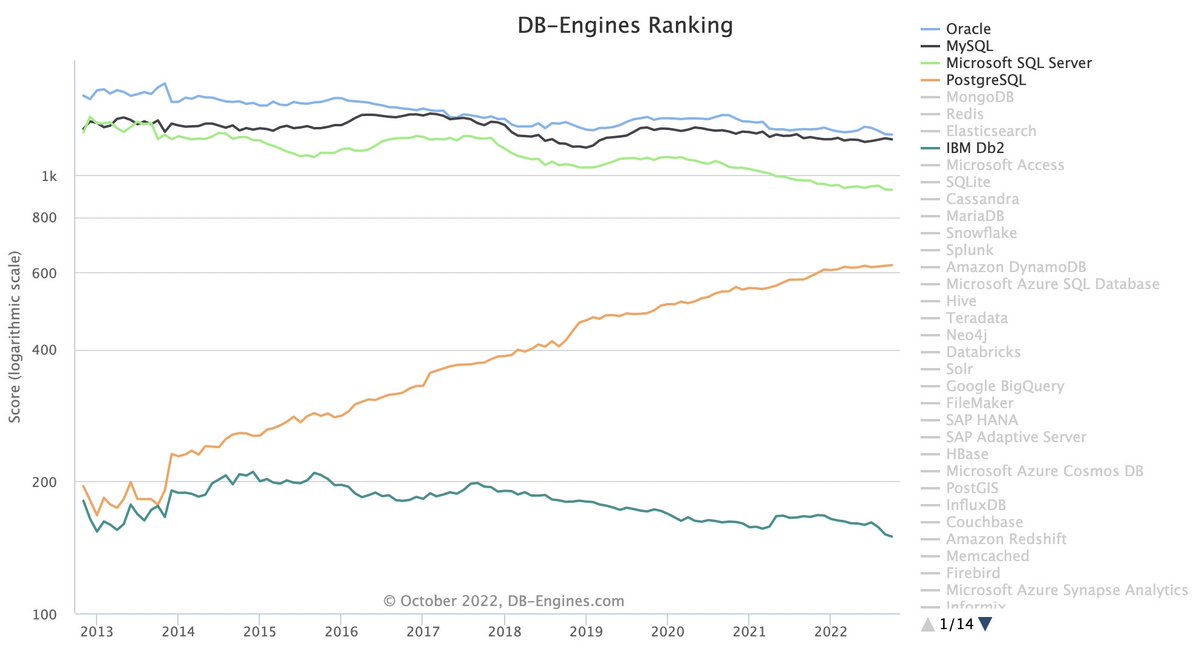
Talking with a friend about Postgres and DB-Engines database trends (db-engines.com/en/ranking_tre…), it strikes me that all of the big relational databases are falling relative to others, with Postgres gaining share at their expense. A few thoughts as to why this makes sense (1/n) pic.twitter.com/Y85p3yl2W4

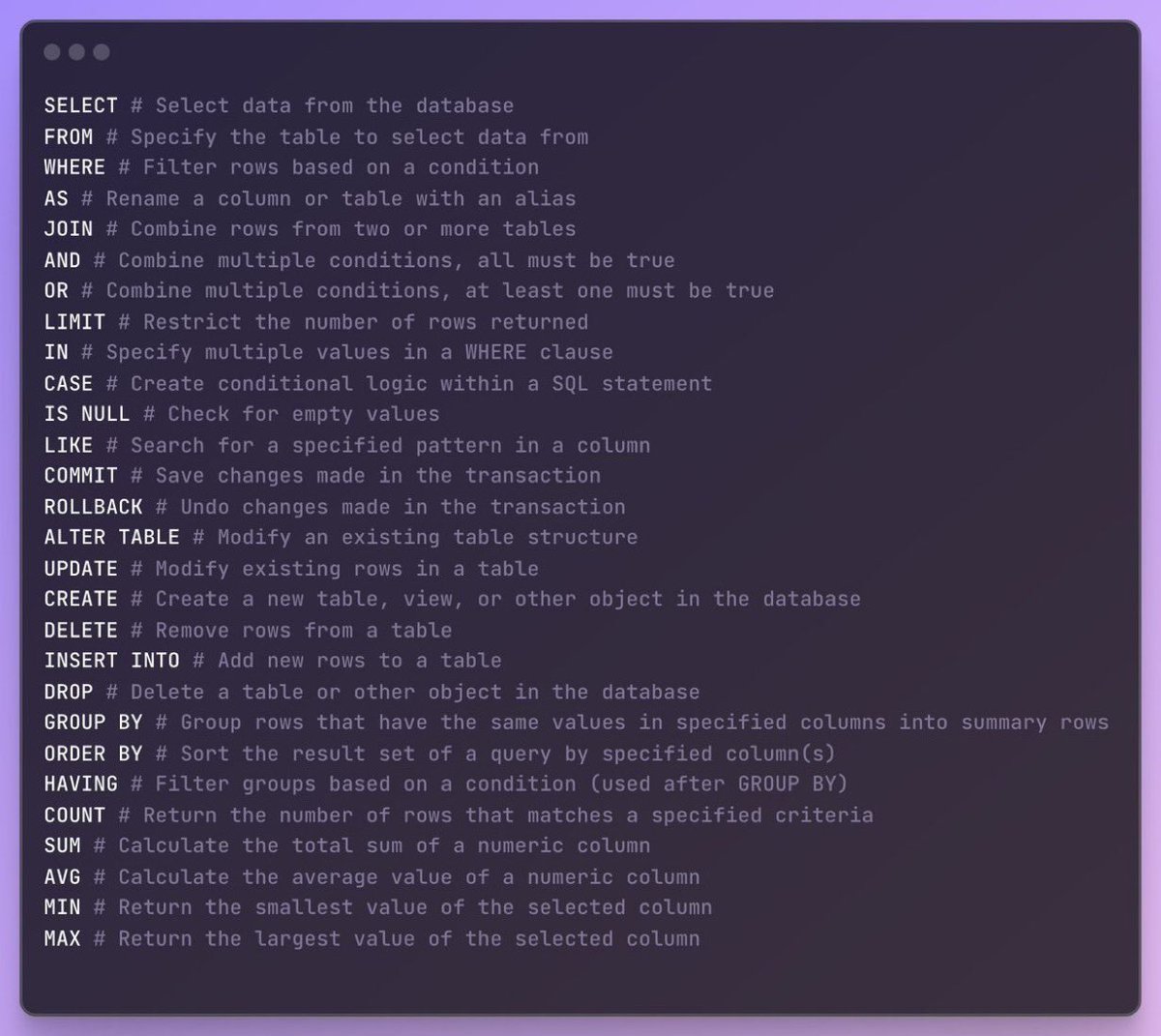
Most comprehensive SQL cheatsheet on the web: (link to PDF below) pic.twitter.com/37X8RawLPx


GraphQL doesn't create an n+1 problem, the problem was already there. The challenge is that it moves it to a place where it's less obvious how to solve it. This is because you need some way of triggering batch loads, and this is going to vary per language and implementation.

I wrote a bit about how you can use MySQL to efficiently query records based on distance. Searching over several million rows, we're able to get our queries down to ~100ms using a computed column, some clever indexing, and a bounding box. aaronfrancis.com/2021/efficient…