🫣 A hotel with an “Avatar”-like view has been found in China A woman showed a room tour of a futuristic hotel set among karst mountains in the city of Guilin. It looks spectacular, but the price matches the view — about $400 per night. pic.x.com/TLatNiLDxV

Oh my goodness, I am in love with this concept!! So ideal for a Family compound or a private group home or private nursing home!! I can see me and my children living here forever with gardens and livestock!! pic.x.com/10CKy6ApL5
Vitamin C literally ERASES wrinkles Researchers had 10 patients apply a vitamin C complex (10% ascorbic acid + 7% lipid-soluble form) to one side of their face for 12 weeks, then took skin biopsies to see what happened at the cellular level. Results: Clinical evaluation showed pic.x.com/pBoyHTzDO0

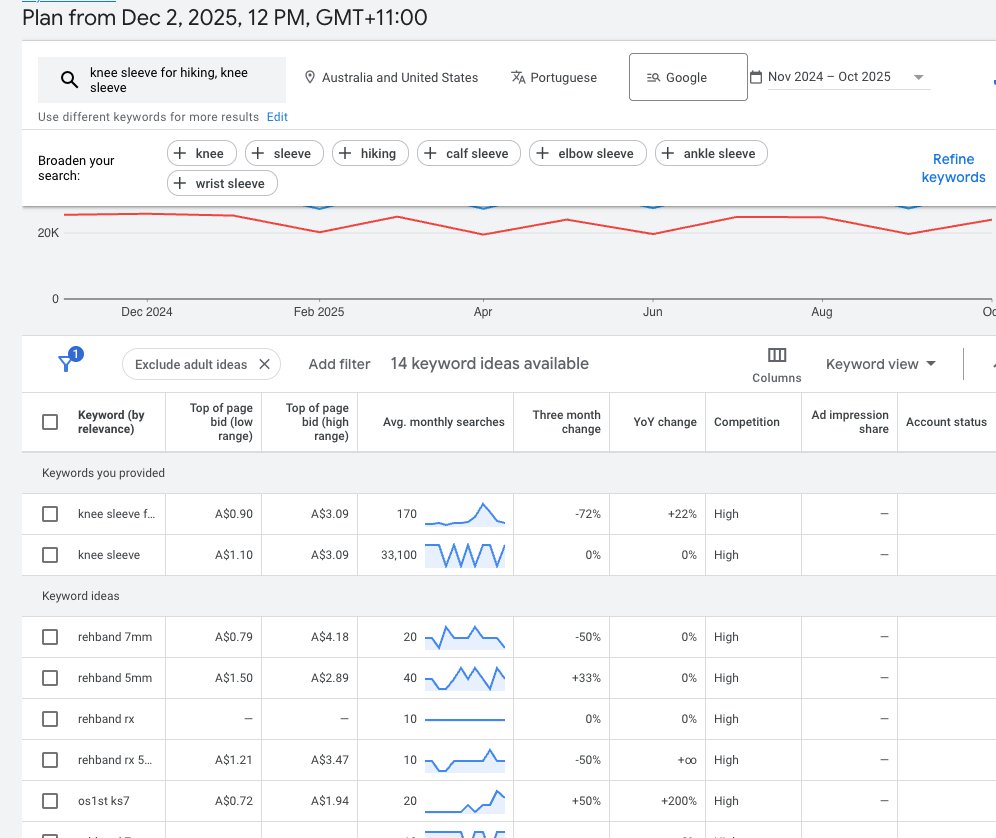
i'm sick of seeing Google Ads dudes telling people to just "do keyword research" instead of actually showing them how. so I'm gonna drop our entire keyword research process today for $0. here’s how to find and scale profitable keywords fast: pic.x.com/9ZEbcUys6C
26 weapons grade parenting tips: 1/ Give them a "heads up," 5 minutes until bedtime, 10 minutes before leaving the playground 2/ Look at the world more through their eyes 3/ Don’t discipline like an angry madman. Stay calm and firm, model how you want THEM to resolve conflict
Here's a collection of useful patterns I've found after vibe-coding 150 different single-file HTML tools over the past couple of years simonwillison.net/2025/Dec/10/ht… pic.x.com/UuN4EfupAs

Finally, AI designs you can edit. Moda - create brand assets on a fully editable canvas. This is not another ChatGPT or nano banana wrapper. We actually taught an agent layout, typography, and color. We gave it taste. Use it for slides, social, infographics, e-books … pic.x.com/0AgNYpHvfb
Marriage (or any positive romantic relationship) is sustained by grace, not emotional thrill. It is this grace that births patience and positive communication. You can have everything but if you don't have grace, you do not belong to the institution. I would define grace here x.com/SkyTheViking/s…
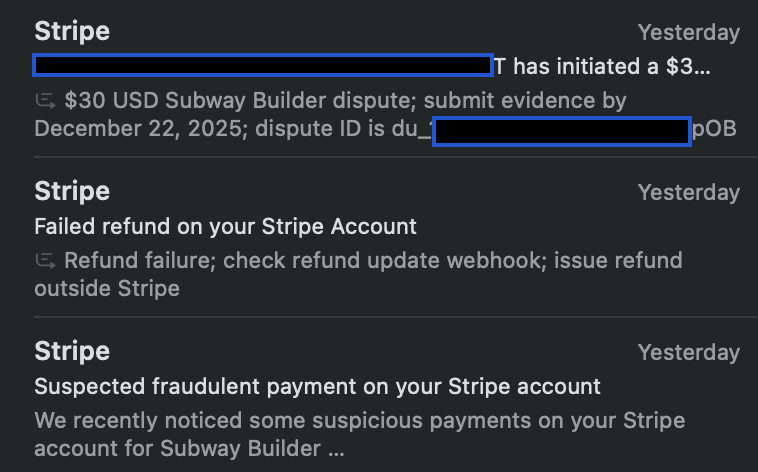
1. Customer buys product 2. Stripe warns me of fraud so I refund the customer 3. Bank doesn't accept refund 4. Customer files dispute 5. I have to pay fees for making a fraudulent payment This system is insane pic.x.com/EGOirgEGhR
Bro made a command center fit for the Batman pic.x.com/wq0JNzfRud
I’ve been reading and reviewing a lot of info about homeschooling from the seasoned vets I’ve met in person and online. Their kids are all successful and intelligent people. And here are a few notes I’ve gathered: 1. Start every session with prayer 2. Kids learn best in the
99% of oncologists start with scans. One of the most famous biologic cancer doctors in Europe does something completely different. The second a woman is diagnosed with breast cancer, Dr. Thomas Rau (medical director of Paracelsus Clinic, Switzerland) says: “Open your mouth.” pic.x.com/Up8WwjIE1b
Do this one trick in @jakubkrehel's article about shadows and you'll 10x your design chops. jakub.kr/work/shadows pic.x.com/7bkK8nFB4e

You are looking at a human brain tumor literally melting away in months. Before → After scans just released by Dr. Patrick Soon-Shiong, the billionaire surgeon who invented Abraxane and owns the LA Times. This patient had already failed maximum radiation, chemotherapy, and pic.x.com/pFixTDTDMc
Real talk: You're going to screw up your kids Not in a traumatic way (hopefully), but in little ways you won't even realize until they're 25 and mentioning it casually. "Yeah, Dad was always on his phone at dinner" or "Dad never really asked about my day." The goal isn't
The only marriages that survive decades are the ones where both people outgrow their illusions, not each other. A few hard truths most couples avoid: At some point, love becomes logistics. If you can handle bills, stress, ageing parents, health scares and bad days without x.com/mattvanswol/st…
First teaser for the ‘SCRUBS’ revival series. Premiering February 25 on ABC and Hulu. pic.x.com/0pQoCGGDtO
Incredible website makingsoftware.com
• Personal space is frequently invaded, no concept of queuing, people try to push past you even in formal settings like airport security or banks. Often will not even make eye contact when doing so, just push into you and try to push past you. Every time you queue you have to be pic.x.com/q9UPnMDAC3

you gotta follow AriAtHome. dude walks around NYC with his mobile streaming/production rig, composing beats for people to sing & rap to. sooo much talent pic.x.com/DsvDCqIDGo
The mediocre don't just quietly underperform. They hang out together. * They hang out at the office together. * They hang out at events together. * They convince each other to do mediocre marketing programs. * They convince each other 15%-20% growth is fine * The convince each
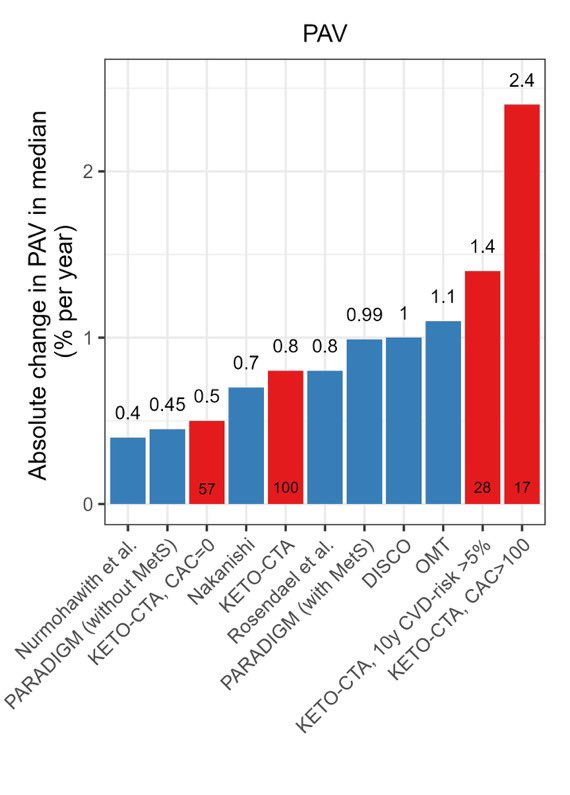
New study shows that the ketogenic diet significantly increases the risk of heart attack and stroke. Social media influencers in shambles. pic.x.com/3dnKAyUam4
DSPy's biggest strength is also the reason it can admittedly be hard to wrap your head around it. It's basically say: LLMs & their methods will continue to improve but not equally in every axis, so: - What's the smallest set of fundamental abstractions that allow you to build x.com/DSPyOSS/status…
agenetic interfaces will eat chat interfaces. that doesn’t mean there’s not an input filed to type instructions in... but the job of talking to AI models will be mostly done by AI models. pic.x.com/Hdw9TLeOER
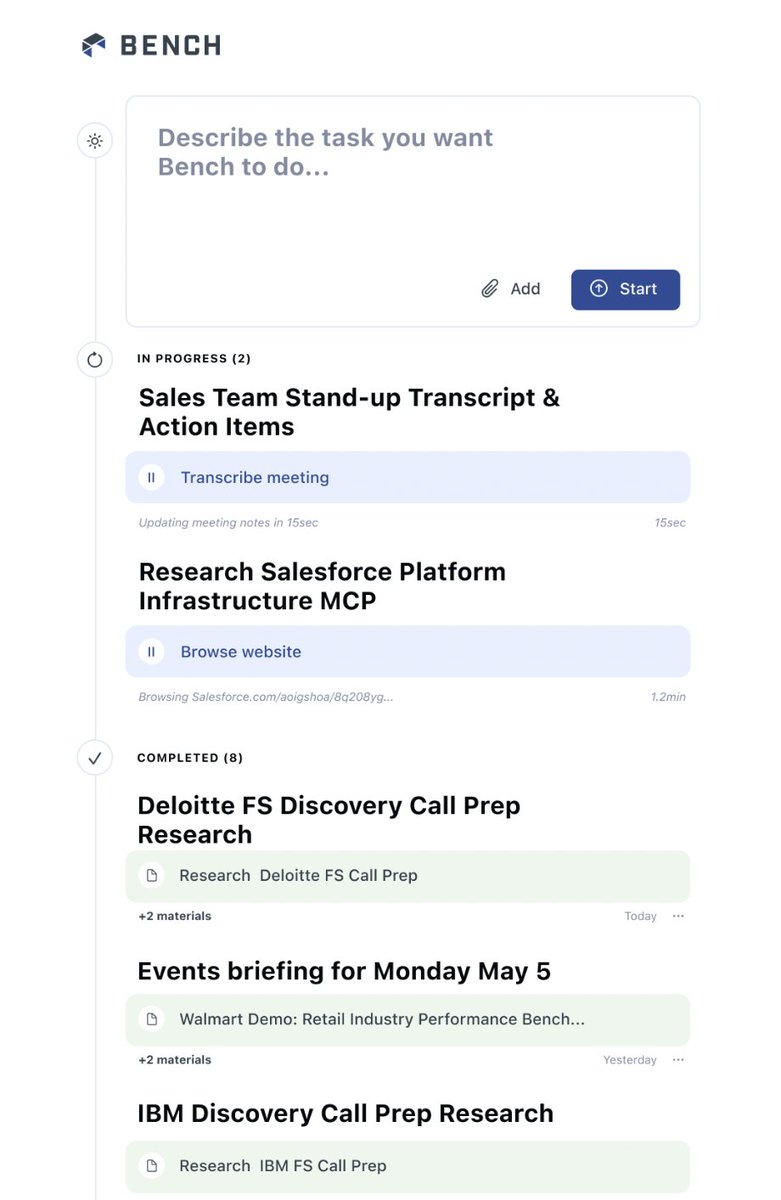
I am excited to announce my new business model interfacer.co Your all-in-one design partner for startups that value speed, clarity, and good taste. faster, together! wish me luck pic.x.com/BjJir9y05j
ADHD is like you wake up every day and have to rebuild the cultural fabric of an entire civilization in your mind from scratch in order to figure out whether you're supposed to, like, do the dishes or whatever
losing my mind over this group of 30 friends who not only actually built a village together but also co-own a factory in this idyllic area? pic.x.com/RtYQneACYH

How to know if someone is emotionally mature: pic.x.com/RqkYoK0Ch9
low key obsessed with @inertiajs + Rails + React. I built this Notion like UI in a day (and I don't know React or Typescript). Not even sure if I'm doing it right (am I supposed to redirect to the parent page if I'm just updating a component??) but it just works ™️ pic.x.com/iJvMzln6Eb

Kids should not be so depressed about school that you can infer the school calendar based on suicide attempts. pic.x.com/IGBMEAOgws